
Modelling Public Sentiment in Twitter: Using Linguistic Patterns to Enhance Supervised Learning
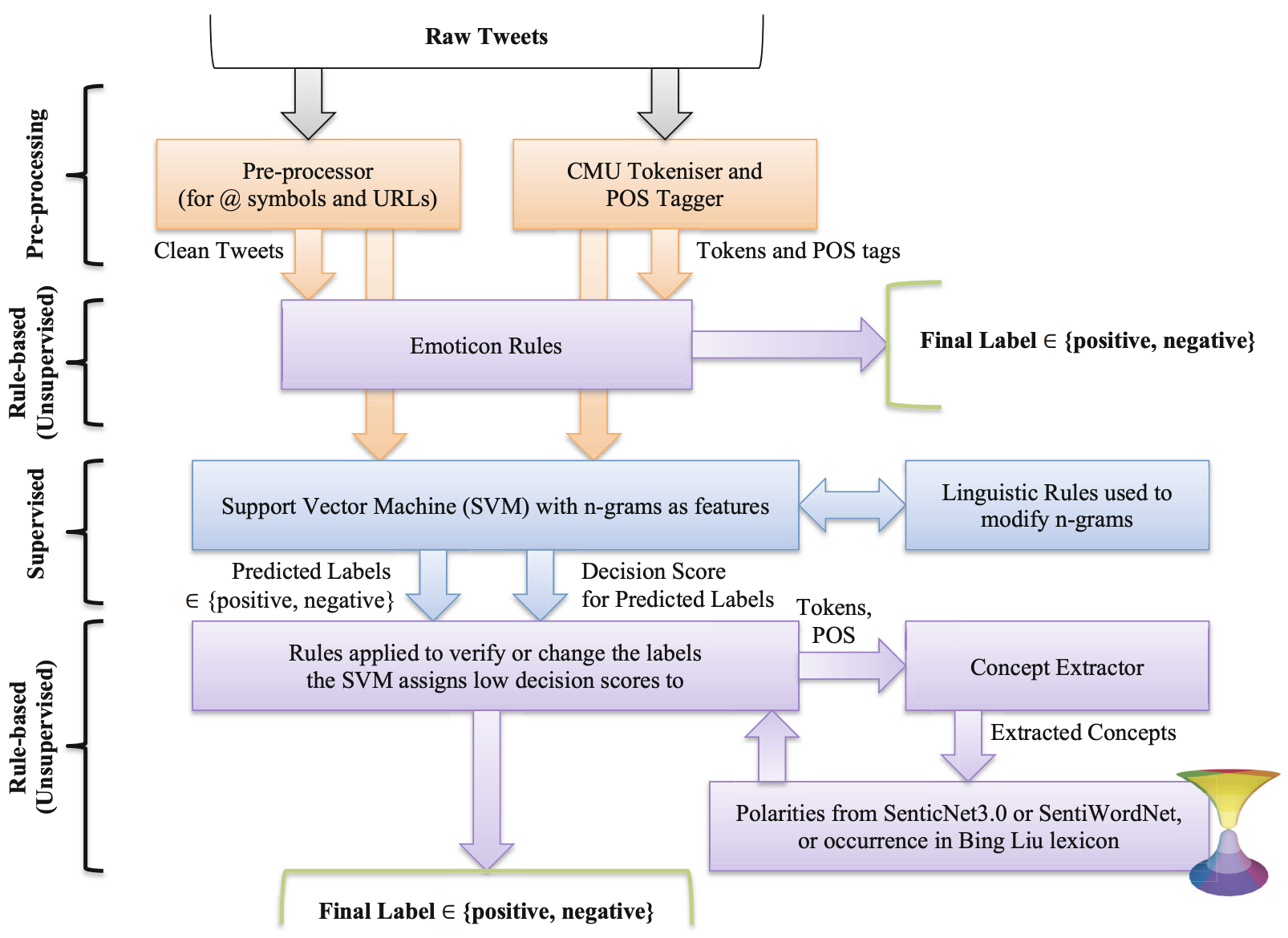
This paper describes a Twitter sentiment analysis system that classifies a tweet as positive or negative based on its overall tweet-level polarity. Supervised learning classifiers often misclassify tweets containing conjunctions such as "but" and conditionals such as "if", due to their special linguistic characteristics. These classifiers also assign a decision score very close to the decision boundary for a large number tweets, which suggests that they are simply unsure instead of being completely wrong about these tweets. To counter these two challenges, this paper proposes a system that enhances supervised learning for polarity classification by leveraging on linguistic rules and sentic computing resources. The proposed method is evaluated on two publicly available Twitter corpora to illustrate its effectiveness.
Publication: Chikersal, P., Poria, S., Cambria, E., Gelbukh, A., & Siong, C. E. (2015). Modelling Public Sentiment in Twitter: Using Linguistic Patterns to Enhance Supervised Learning. In International Conference on Intelligent Text Processing and Computational Linguistics (CICLing 2015) (pp. 49-65).
Related Workshop Paper: Chikersal, P., Poria, S., & Cambria, E. (2015). SeNTU: Sentiment Analysis of Tweets by Combining a Rule-based Classifier with Supervised Learning. In Proceedings of the 4th International Workshop on Semantic Evaluations (pp. 647-651). Association for Computational Linguistics.
My Contributions: Led data crawling, parsing, and analysis. Developed the data analysis methodology. Analyzed data using machine learning. Presented results to the team. Led paper writing.